
요 근래 삼일간 함수형 프로그래밍을 배워보자! 라고 생각하고 책도 빌려보고, 다양한 블로그 글들, 강의 영상들을 보면서 개념들을 훑었었다.
보면서 느꼈던 것은 커링, 모나드, 펑터 이런 개념들을 보면서 "그런 개념들이 있는건 알겠어.(사실 모름) 그런데 그거 쓰면 뭐가 좋은데?" 라는 의문이 계속 머리속을 맴돌았다. 그러면서 흥미를 잃어가던 와중 운 좋게 이 영상을 보게 되었고, 보자마자 "와! 나도 앞으로도 이런식으로 코딩 해야겠다" 라고 느꼈다.
본 게시글엔 적지 않겠지만 영상을 보며 감탄을 금치 못했던 부분중 하나가 이런 시나리오였다.
어떤 비동기적인 요청이 존재하는
job메소드가 존재할 때 최소한job메소드는 최소 5초 이후에 매번 재실행되어야 한다고 가정한다. (요청이 완료 될 때 까지 재요청 하면 안된다.)job메소드는 5초보다 빨리 끝날 수도, 늦게 끝날 수도 있을 때 어떻게 구현 할 것인가?
자바스크립트를 탄탄히 알고 있는 사람이였다면 쉽게 답 할수도 있었겠지만 나는 질문만 보고
아.. 조건문을 어떻게 세워야하지 .. 비동기적인 처리니까 어쩌구 저쩌구 ... 이런 쓸데 없는 고민을 하고 있을 때 그냥 단순히 몇 초를 기다리는 delay 라는 메소드를 만들어 둔 후 Promise.all([delay(5) , job]) 을 때려버리더라. 단순한 처리로 그냥 Math.max(1,2) 란 똑같은 매우 단순한 코드이기에 테스트코드도 필요 없었다.
 감탄을 금치 못하는 내 모습
감탄을 금치 못하는 내 모습
요 안에서 Promise.all 의 기능을 사용했다는 것이 중요한게 아니라 Promise 라는 개념을 Future Monad 로 바라보고, 모든 함수를 값으로 바라 봤을 때 발생하는 장점, 지연 평가에 대한 이야기들이 종합적으로 이어졌을 때 보자마자 박수치는 원숭이 인형마냥 박수를 치고 있었다.
짝짝짝
본격적으로 함수형 프로그래밍을 알아가기 위해 필요한 사전 지식들을 정리해보자
함수형 프로그래밍의 정의
함수형 프로그래밍은 계산을 함수와 함수의 연산 으로 추상화한 체계인 람다 대수 를 이론으로 하여 순수 함수 들을 이용해 불변성 을 통해 안정성을 높히고 고차 함수를 활용 하여 함수의 조합으로 프로그래밍을 하는 패러다임을 말한다.
익숙치 않은 단어들이 보여 하나씩 정리해본다.
함수를 연산?
연산이 가능하단 것은 연산자로 인해 연산 가능한 피연산자를 의미한다.
1 + 2 = 3 에서 1,2,3 은 각자 + , = 등과 같은 산술 연산자에 의해 연산 가능한 값, 원시값이다.
연산은 변수 할당에도 사용 되는데 const user = {name : '멋쟁이'} 처럼 user 라는 변수에게 = 연산자에 의해 할당 가능한 객체로, 연산 가능한 객체인 일급 객체 라 정의한다.
연산 가능한 값, 일급 객체들은 변수에 할당 가능하고, 함수의 인자로 전달 가능하고 함수의 반환 값으로도 사용 가능 하다.
자바스크립트에서는 함수도 일급 객체 로 변수에 할당 가능하고, 함수의 인자로 전달 가능하고, 함수의 반환값으로도 사용 가능하다.
const foo = ()=>{}; // 변수에 할당 가능
const go = (val , func)=> func(val); // 함수에 인자로 함수를 건내는 것이 가능
const bar = ()=> ()=> console.log('hi!'); // 함수에서 함수를 반환하는 것이 가능자바스크립트는 함수를 일급 객체로 취급 하여 함수형 프로그래밍 패러다임을 사용 하는 것을 가능하게 한다.
람다 대수 이론은 잠깐 스킵.. 너무 어렵다.
순수 함수
순수 함수 (pure function) 는 부작용(side effect) 이 없는 함수로 함수의 실행외 외부에 영향을 미치지 않는 함수를 뜻한다.
여기서 말하는 순수하단 의미는 함수가 호출되는 시점에 상관없이, 함수에 사용된 인수가 같다면 반환값이 매번 같음을 보장한다는 것이다.
const add = (a,b)=> a+b; 같은 함수는 a,b 의 값이 매번 같다면 어느 시점에 실행하나 값은 매번 동일하다.
하지만 const getRandomNumber = ()=> Math.random(); 이나 const getDB = ()=> db.데이터긁어오기(); 같이 호출 시점에 영향을 받는 함수들은 순수함수라고 하지 않는다.
여기서 말하는 부작용이란 함수가 정의된 컨텍스트 외부 상태에 영향을 미치는 행위 를 의미한다. 예를 들어 외부에 선언된 변수의 값을 변경하거나 데이터베이스를 조작한다거나 DOM 을 조작한다거나 로그를 찍는다는 등의 행위를 말이다.
순수함수로만 이뤄지면 뭐가 좋은데?
순수함수는 매번 입력이 같다면 출력이 같기에 예측 가능하고 안전 하다.
순수함수는 외부 상태의 변화에 의존하지 않고 단순히 입력값에만 의존하기 때문이다.
이러한 특징으로 인해 순수함수는 테스트하기 용이하다.
어떤 표현식의 결과를 표현식 자체로 대체해도 프로그램의 동작이 변경되지 않는 다는것을 참조 투명 하다고 한다. 예를 들어
const a = 1; console.log(a);라는 코드가 있을 때 표현식의 결과인a를 표현식 자체인1로 변경해도 프로그램의 동작이 변경되지 않는다.순수 함수도 그렇다.
const foo = (a,b)=> a+b; const result = foo(1,2);란 표현식에서foo(a,b)를foo함수의 표현식인a+b로 변경해도result의 값이 변경되지 않는다.이렇게 순수 함수는 참조 투명성 을 지킨다.
생각해보면 a,b 라는 값을 받아 두 값을 더하는 함수는 테스트하기 쉽지만, DB에서 어떤 데이터를 읽거나 쓰는 함수는 해당 함수를 호출 할 때 운이 안좋게 DB에서 그 데이터가 변경이 일어났다면 함수의 오류없이도 테스트가 실패 할 수 있다.
외부 상태에 의존하지 않는 순수 함수는 독립적이기 때문에 코드를 모듈화 하기 용이하고 재사용하거나 조립하기도 쉬워진다.
불변성
불변성은 순수함수와 큰 관련이 잇다.
변하기 쉬운 상태인 state 는 항상 불안한 폭탄 덩어리다.
변하기 쉬운 상태가 코드의 안정성을 해치는 경우를 생각해보자
let flag = true; // 변경 가능한 값 (mutable)
const func1 = () => {
flag = Math.random() > 0.5; // 외부 상태 변경 1
};
const func2 = () => {
console.log(`flag is ${flag ? "true" : "false"}`);
};
func2(); // flag is false
/**
* 이후 1000줄의 코드들이 존재
*/
const func10 = () => {
flag = !flag; // 외부의 상태 변경 2
};
func10();
/**
* 이후 1000줄의 코드들이 존재
*/
func2(); // flag is truefunc1, func2, ... func10 함수 모두 변하기 쉬운 상태를 참조하거나 변경 할 때 func2 함수는 호출 시점에 따라 결과 값이 달라지며 변하기 쉬운 상태를 참조하는 함수들이 많으면 많을 수록 상태의 흐름을 추적하는 것이 쉽지 않다.
이런 불변성은 함수가 참조하는 값을 인수로만 건내줌으로서 해결 할 수 있는데 이 또한 주의해야 하는 점이 배열이나 객체와 같이 주소에 의한 참조 로 이뤄지는 경우 예기치 못한 부분에서 상태의 변경이 일어날 수 있다는 점이다.
이를 방지하기 위해선 함수에서 객체 등을 연산 할 때 깊은 복사를 통해 새로운 값을 받아 사용하거나, 변경 가능한 변수의 스코프를 최대한 방지해야 한다.
고차함수
고차함수란 함수를 인자로 받거나 함수를 반환하는 함수를 의미한다.
const addWith = (value1: number) => (value2: number) => value1 + value2;
const addWithFive = addWith(5);
console.log(addWithFive(1)); // 6
const multiplyWith = (value1: number) => (value2: number) => value1 * value2;
const multiplyWithFive = multiplyWith(5);
console.log(multiplyWithFice(2)); // 10함수를 인자로 받아 함수를 호출하는 고차 함수의 예시는 다음과 같다.
// 함수를 인수로 받는 고차 함수
const applyOperation = (
operation: (value: number) => number,
operand: number
) => operation(operand);
console.log(applyOperation(addWithFive, 10)); // 15
console.log(applyOperation(multiplyWithFive, 10)); // 50콜백 함수
콜백 함수라는 이름이 붙은 이유는 호출 시점이 실행 흐름에 따라 제어되어 호출되기 때문이다.
위 예시에서 봤듯 콜백 함수로 건내진 addWithFive , multiplyWithFive 의 호출 시점은 전적으로 applyOperation 에 의해 제어된다.
위 예시에서는 콜백 함수가 동기적 콜백함수 형태로 사용 된 것이다.
콜백함수는 비동기적인 형태로 사용되기도 한다. Promise.then,catch 에 건내지는 콜백함수가 대표적인 비동기 콜백 함수이다.
비동기 콜백 함수의 호출 시점은 Promise 안에 존재하는 값 여부에 따라 제어된다.
최근 읽었던 함수형 자바스크립트 프로그래밍 에선 이름에 따라 표현과 상상력에 제약이 생기기 때문에 동기 콜백 함수에 대해서 모든 것을 콜백 함수라 이야기 하지말고 적절한 이름을 붙혀 사용해야 한다고 이야기 한다.
const f = (iterable,callbackFn) => {
const result = [];
for (const item of iterable) {
result.push(callbackFn(item));
}
return result;
};
const callbackFn = // 비밀
console.log(f([1, 2, 3, 4], callbackFn));동기적 콜백 함수들에겐 역할에 따라 명확한 이름이 존재해야 한다고 필자는 주장한다.
예를 들어 필터링에 사용되는 콜백함수는 predicate, 새로운 값으로 변환하는 콜백함수는 mapper , 하나의 값으로 변경하는건 reducer, 순회하는 것은 iterator, 유효성을 검사하는 것은 validator, 이벤트나 작업의 결과를 처리하는 것은 handler 와 같이 말이다.
만일 위 함수에서 const f = (iterable,mapper) => { 였다면 함수의 타입을 적을 때 mapper 형태로 적고 이해할 것이고 const f = (interable, predicate)=>{ 였다면 boolean 을 반환하도록 적도록 뇌가 열렸을 것이다.
용어나 정의는 대충 알았고, 그럼 어떻게 사용할까?
어떤 식으로 시작할지 고민이 많았다. 개념이 명확히 잡히지 않은 상태에서 강의나 포스트들을 보며 바닐라로 직접 만들며 시작하는 편과, 가장 유명한 라이브러리인
lodash/fp를 먼저 익히는 편중 어떤 것이 나을지가 고민이였다.안전한건 라이브러리를 먼저 따라 시작하는 것 같긴한데 뭔가를 배울 때 유연한 사고를 하기에는 바닐라로 시작하는 것이 나을 거 같아 우선 바닐라로 시작한다. 대부분의 코드는 위에서 소개한 코드를 따라 만들었다.
📖 시나리오: 배열에서 정해진 길이까지만 배열을 순회하여 짝수 제곱합
절차 지향적으로 생성된 명령형 코드를 시작으로 하여 차츰 함수형 패러다임에 따라 로직을 수정해 나간다.
각 과정은 코드의 표현식들을 최대한 함수의 연산들로 표현하는 것에 중점을 둔다.
<script>
const main = () => {
const func = (iterable, amount) => {
let i = 0;
let acc = 0;
for (const item of iterable) {
if (item % 2 === 0) {
acc += item * item;
if (++i === amount) {
break;
}
}
}
console.log(acc);
};
const iterable = [1, 2, 3, 4, 5, 6, 7];
func(iterable, 1); // 4
func(iterable, 2); // 20
func(iterable, 3); // 56
};
main();
</script>대부분의 표현식을 함수의 연산으로 수정해보자
함수 프로그래밍 패러다임에선 모든 표현식을 함수로 변경하여 생각한다. 즉 불필요한 반복문이나 조건문등을 함수로 변환하여 사용한다.
if 문 filter로 변경
조건문에 해당하는 if 문을 filter 메소드로 수정해보자
<script>
const L = {};
L.filter = function* (predicate, iterable) {
for (const item of iterable) {
if (predicate(item)) {
yield item;
}
}
};
const main = () => {
const func = (iterable, amount) => {
let i = 0;
let acc = 0;
for (const item of L.filter((item) => item % 2 === 0, iterable)) {
acc += item * item;
if (++i === amount) {
break;
}
}
console.log(acc);
};
const iterable = [1, 2, 3, 4, 5, 6, 7];
func(iterable, 1); // 4
func(iterable, 2); // 20
func(iterable, 3); // 56
};
main();
</script>제네레이터를 이용한 L.filter 메소드를 이용해 if 문을 제거해주었다.
제네레이터와 반복문의 관계는 MDN의 문서를 참고하자!
제네레이터는 이터러블을 반환하며for문은 이터레이터의.next()메소드를 호출하여 평가한다.
제네레이터를 왜 쓰는데? 에 대한 의문은 추후 의문이 뻥 뚫린다.
L이란 네임스페이스에 메소드를 정의하는 이유는 지연평가 되는 메소드등을 표현하기 위한 방식이다. 지연평가가 어떻게 이뤄지는지는 추후 설명한다.
직접 연산에서 map 으로
위 함수에서 acc += item * item 의 경우 어떠 값을 받아 새로운 값을 반환하는 map 함수로 대체 할 수 있다.
<script>
...
L.map = function* (mapper, iterable) {
for (const item of iterable) {
yield mapper(item);
}
};
const main = () => {
const func = (iterable, amount) => {
let i = 0;
let acc = 0;
for (const item of L.map(
(x) => x * x,
L.filter((item) => item % 2 === 0, iterable)
)) {
acc += item;
if (++i === amount) {
break;
}
}
console.log(acc);
};
const iterable = [1, 2, 3, 4, 5, 6, 7];
func(iterable, 1); // 4
func(iterable, 2); // 20
func(iterable, 3); // 56
};
main();
</script>if 문에서 take 로
이번엔 조건문에서 take 란 메소드로 변경하도록 한다.
take 메소드는 iterable 을 특정 길이까지만 가지고 반환하겠다는 것을 의미한다.
<script>
...
const take = (length, iterable) => {
const result = [];
for (const item of iterable) {
result.push(item);
if (result.length === length) {
return result;
}
}
return result;
};
const main = () => {
const func = (iterable, amount) => {
let acc = 0;
for (const item of take(
amount,
L.map(
(x) => x * x,
L.filter((item) => item % 2 === 0, iterable)
)
)) {
acc += item;
}
console.log(acc);
};
const iterable = [1, 2, 3, 4, 5, 6, 7];
func(iterable, 1); // 4
func(iterable, 2); // 20
func(iterable, 3); // 56
};
main();
</script>for 문에서 reduce로
이제 모든 반복문을 돌며 acc 값을 계산하는 반복문만 남았다. 해당 반복문을 reduce 란 메소드로 변경하도록 한다.
reduce 메소드는 iterable 과 초기값 acc (acleartor) 를 받아 인수로 받은 reducer 에게 iterable 의 각 아이템들과 acc 간의 값을 계산하여 반환한다.
<script>
...
const reduce = (reducer, acc, iterable) => {
for (const item of iterable) {
acc = reducer(acc, item);
}
return acc;
};
const add = (a, b) => a + b;
const main = () => {
const func = (iterable, amount) => {
const result = reduce(
add,
0,
take(
amount,
L.map(
(a) => a * a,
L.filter((a) => a % 2 === 0, iterable)
)
)
);
console.log(result);
};
const iterable = [1, 2, 3, 4, 5, 6, 7];
func(iterable, 1); // 4
func(iterable, 2); // 20
func(iterable, 3); // 56
};
main();
</script>func 함수를 순수 함수로 변경해보자
위에서 예시로 들었던 외부 세계에 영향을 미치지 않는 함수인 순수함수로 만들기 위해 func 함수가 외부에 영향을 미치는 console.log 문을 외부에서 처리하도록 해주자
그러기 위해 func 함수는 이제 result 를 반환하기만 하면 되는데, 이 과정속에서 func 함수는 함수들의 연산으로 표현 가능하다.
<script>
const main = () => {
const func = (iterable, amount) =>
reduce(
add,
0,
take(
amount,
L.map(
(a) => a * a,
L.filter((a) => a % 2 === 0, iterable)
)
)
);
const iterable = [1, 2, 3, 4, 5, 6, 7];
console.log(func(iterable, 1)); // 4
console.log(func(iterable, 2)); // 20
console.log(func(iterable, 3)); // 56
}
main();
</script>위 코드에 익숙치 않으면 도저히 괴랄하게 생긴 저 표현식이 뭐가 낫다는건지 공감하기 힘들지만
코드의 흐름을 위에서 아래로 읽던 절차 지향적인 코드와 달리 함수형 프로그래밍은 오른쪽에서부터 왼쪽으로 읽어나가면 코드를 읽기가 쉽다.
인수로 받은 iterable 을 a % 2 === 0 인 것으로 filter 하고, 각 요소들을 a*a이 되도록 map 하고 amount 만큼 take 한 후 0 에서부터 시작하여 add 함수로 reduce 해라
와우, 이렇게 읽으면 어떤 절차가 있는지 단번에 이해 할 수 있다.
pipe 를 통해 절차를 표현하자
강의 영상에선
go라는 메소드로 정의했지만 나는pipe란 이름으로 정의하도록 한다.
func 메소드는 iterable 을 filter -> map -> take -> reduce 의 순서로 각 순수함수들을 절차에 따라 시행하여 반환하는 메소드이다.
이런 순수함수들을 절차에 따라 수행하는 pipe 메소드를 정의해주도록 한다.
이 과정속에서 reduce 메소드를 조금 수정해줘야 하는데 const reduce = (reducer, acc, iterable) => {} 의 인자에서 acc 자체가 iterable 들을 담고 있는 경우 세 번째 인자를 주지 않아도 되도록 수정한다.
<script>
...
const pipe =
(...iterators) =>
(value) => {
return reduce((acc, func) => func(acc), value, iterators);
};
const main = () => {
const func = (iterable, amount) =>
pipe(
(iterable) => L.filter((a) => a % 2 === 0, iterable),
(iterable) => L.map((a) => a * a, iterable),
(iterable) => take(amount, iterable),
(iterable) => reduce(add, 0, iterable)
)(iterable);
...
}
</script>이렇게 각 순환 가능한 iterator 들을 인수로 받아 인수로 받은 순수 함수들을 이용해 reduce 해가는 고차함수pipe 를 정의해주게되면 func 메소드는 iterable 을 인수로 받아 각 filter , map , take , reduce 해나가는 절차를 표현해줄 수 있다.
currying 해보자
currying 이란 다중 인수를 갖는 함수들의 함수열로 바꾸는 것이다. 예를 들어 이런 코드를 의미한다.
// 다중 인수를 한 번에 받는 경우
function add(x, y) {
return x + y;
}
// 다중 인수를 나눠 받는 경우
function curriedAdd(x) {
return function (y) {
return x + y;
};
}
const add5 = curriedAdd(5);
console.log(add5(3)); // 출력: 8커링은 다중 인수가 준비되는 시점이 다를 때 사용된다.
const func = (iterable, amount) =>
pipe(
(iterable) => L.filter((a) => a % 2 === 0, iterable),
(iterable) => L.map((a) => a * a, iterable),
(iterable) => take(amount, iterable),
(iterable) => reduce(add, 0, iterable)
)(iterable);이전 함수를 보면 pipe 안에서 filter , map,take,reduce 등의 메소드는 본인 이전에 있는 메소드가 호출되어 반환한 결과값 iterable 을 인수로 받아 호출되어야 하기 때문에 한 번 더 메소드 형태로 감싸진 모습을 볼 수 있다.
<script>
const curry =
(callback) =>
(firstArgument, ...rest) =>
rest.length
? callback(firstArgument, ...rest)
: (...args) => callback(firstArgument, ...args);
</script>다음과 같이 다중 인수를 받는 콜백 메소드를 인수로 받아 인자가 두 개 이상 들어오면 즉시 실행 시키고, 하나만 들어오면 나머지 인수들을 받아 결과값을 반환하는 curry 메소드를 생성해준다.
curry메소드는 구현하기 나름이며function.arguments와 재귀 함수를 이용하여 인수를 한 번에 모두 받거나, 나눠 받는 등의 구현이 가능하다. 이는 추후 더 공부하고 적도록 한다 🔥
 curry 메소드의 사용 예시
curry 메소드의 사용 예시
const func = (iterable, amount) =>
pipe(
(iterable) => L.filter((a) => a % 2 === 0, iterable), // 1
(iterable) => L.map((a) => a * a, iterable), // 2
(iterable) => take(amount, iterable), // 3
(iterable) => reduce(add, 0, iterable) // 4
)(iterable); // 0L.filter , L.map , take , reduce 메소드 모두 curry 메소드로 감싸주게 되면 각 메소드들은 다음과 같이 사용 가능해진다.
L.filter(()=>{})(iterable) , L.map(()=>{})(iterable), take(amount)(iterable), reduce(add)(0,iterable)
reduce 를 제외한 메소드들이 이전에 평가된 메소드의 반환값인 iterable 값을 받아 호출되며 reduce 메소드도 통일시켜주기 위해 코드를 일부 수정해주도록 한다.
const reduce = curry((reducer, acc, iterable) => {
if (iterable === undefined) {
iterable = acc[Symbol.iterator]();
acc = iterable.next().value;
}
for (const item of iterable) {
acc = reducer(acc, item);
}
return acc;
});이렇게 되면 reduce(add , [1,2,3,4]) 와 같이 값이 들어오면 reduce 는 iterable 인 [1,2,3,4] 의 첫 번째 원소를 acc으로, 반복문에 들어가는 iterable 은 [2,3,4] 만 사용하게 된다.
이제 모든 메소드들이 메소드(콜백함수)(iterable) 형태로 통일 되었기에 func 메소드는 다음처럼 리팩토링 가능하다.
const func = (iterable, amount) =>
pipe(
L.filter((a) => a % 2 === 0),
L.map((a) => a * a),
take(amount),
reduce(add)
)(iterable);여기서 추가로 pipe 메소드도 reduce 를 이용해 생성되었기에 다음처럼 변경 가능하다.
// 변경 전
const pipe =
(...iterator) =>
(value) => {
return reduce((acc, func) => func(acc), value, iterator);
};
// 변경 후
const pipe = (...iterator) => reduce((acc, func) => func(acc), iterator);reduce 메소드에서 초기값을 건내주지 않으면 ...iterator 들의 첫번째 원소를 초기값으로 이용했기 때문이다.
그럼 다시 func 메소드는 이처럼 사용 할 수 있다.
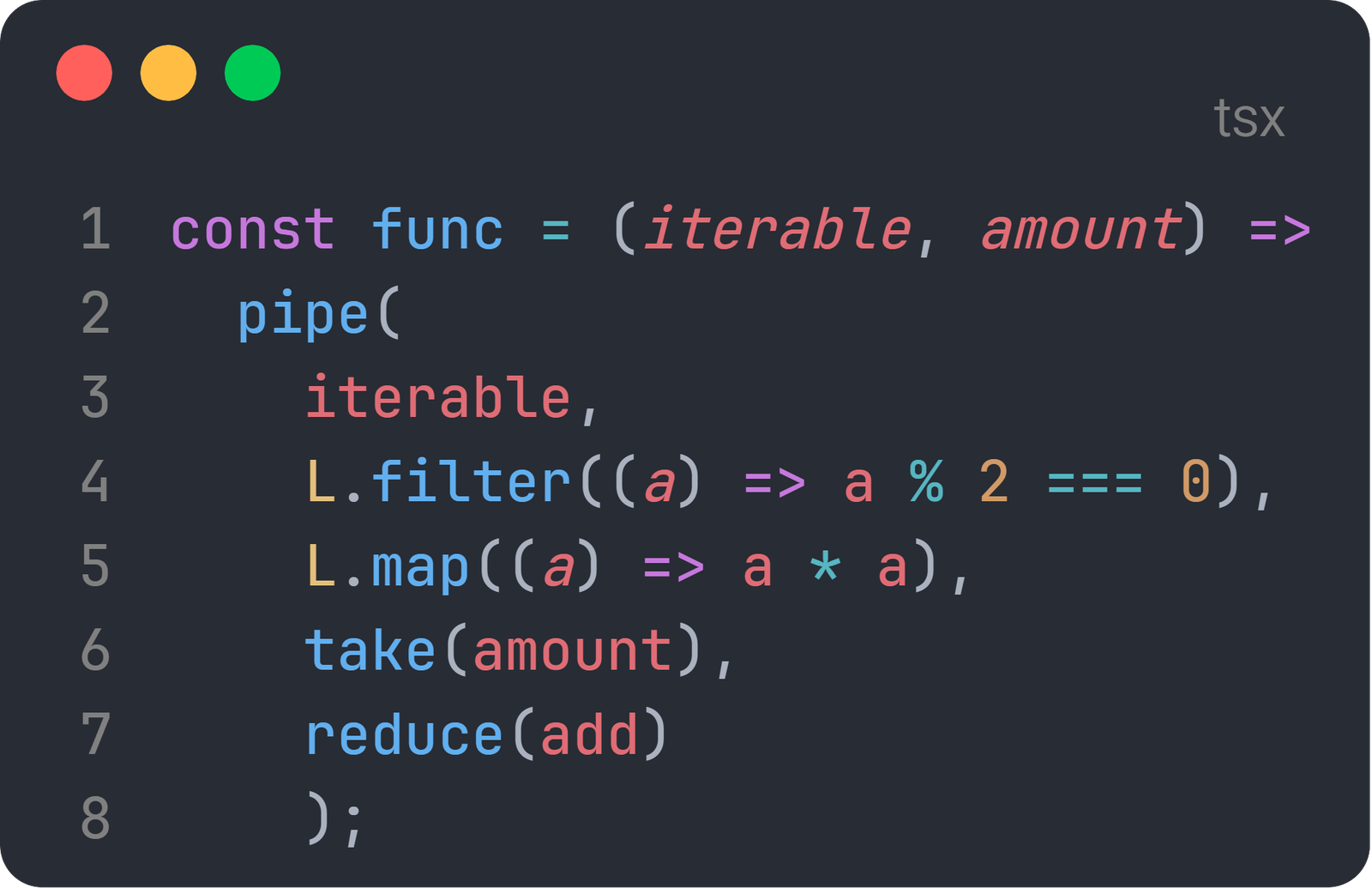
const func = (iterable, amount) =>
pipe(
iterable,
L.filter((a) => a % 2 === 0),
L.map((a) => a * a),
take(amount),
reduce(add)
);결과 중간점검
이전 절차지향적으로 명령형으로 작성된 func 메소드와 현재 선언적으로 작성된 func 메소드를 비교해보자
// 명령형으로 작성된 func 메소드
const func = (iterable, amount) => {
let i = 0;
let acc = 0;
for (const item of iterable) {
if (item % 2 === 0) {
acc += item * item;
if (++i === amount) {
break;
}
}
}
console.log(acc);
};
// 선언적으로 생성된 func 메소드
const func = (iterable, amount) =>
pipe(
iterable,
L.filter((a) => a % 2 === 0),
L.map((a) => a * a),
take(amount),
reduce(add)
);이전 메소드는 원하는 결과값인 acc 를 얻기 위해 item를 2로 나눠 확인하고, i를 증가시킨 후 amount 양과 비교하여 같으면 멈추고 .. 등 어떻게 동작시킬지 (how)에 집중 하는 명령형 코드였다면
선언적으로 생성된 func 는 어떤 일(what)을 할 것 인지 선언하는 코드이다.
코드의 가독성 측면에서 나는 선언적으로 생성된 코드가 더 좋다고 생각이 든다. 어떤 일을 해야 할지에 대해 표현이 되어 있기 때문에 추후 시간이 지나 다시 코드를 살펴 봤을 때 이게 무슨 일을 하고, 이게 어떤 흐름으로 결과값을 반환 할지가 명확해 보이기 때문이다.
메소드 체이닝과의 차이
사실 여기까지 보면 자바스크립트 본연의 메소드인 메소드 체이닝과 크게 달라보이지 않는다.
const amount = 2;
const reseult = iterable
.filter((a) => a % 2 === 0)
.map((a) => a * a)
.slice(0, amount)
.reduce(add);
console.log(reseult); // 20, 이전 pipe 로 감싼 메소드와 결과값이 같다.차이점은 메소드 체이닝은 이전 로직이 모두 완료 된 후 실행되지만 이전에 제네레이터를 이용해 평가를 지연시킨 로직은 다음값이 필요 할 때에만 결과값이 실행 된다는 점이다.
시간 복잡도 측면에서 바라보면 저 메소드 체이닝에서 filter 의 경우 O(N) 의 복잡도를 갖는다. 본인이 호출된 시점에 모든 배열을 순회하여 filter 할 것이기 때문이다.
만약 iterable 의 배열의 길이가 무지하게 큰데 저 짝수면서 제곱합 것을 2개만 뽑아 모두 더하는 경우 메소드 체이닝으로 구현한 로직은 시간 복잡도 측면에서 매우 좋지 않다.
오히려 복잡도 측면으로 보면 명령형으로 구현하여 원하는 개수가 되면 break 했던 코드가 복잡도 측면에서 더 좋다고 볼 수 있다.
하지만 제네레이터로 구현한 코드의 시간 복잡도는 명령형으로 구현한 것과 동일한 시간 복잡도를 갖는데 각 filter , map , take 메소드에서 for 문 내부에서 로그를 찍도록 하고 바라보자
filter 1
filter 2
map 4
take 4
filter 3
filter 4
map 16
take 16
reduce에도 찍으려 했으나pipe메소드에서reduce를 사용하고 있어 로깅 결과가 조금 이상하더라 파이프라인에 존재하는reduce는take메소드가 모두 평가 된 후 마지막에 한 번 시행된다.
시간복잡도가 for 문으로 돌린 것과 동일하다. 이런 것이 가능한 이유는 L.filter, L.map 이 제네레이터로 구현되어 필요할 때에만 호출되는 지연평가가 일어나기 때문이다.
const func = (iterable, amount) => {
// pipe 함수를 사용하여 함수들을 순차적으로 연결합니다.
return pipe(
iterable, // 1. 초기 데이터(iterable)를 파이프라인에 전달합니다.
L.filter((a) => a % 2 === 0), // 2. 지연 평가 필터링: 짝수만 통과시키는 필터 함수를 생성합니다.
// - iterable의 각 요소는 필요할 때 평가됩니다.
// - 1은 필터링 조건을 만족하지 않으므로 무시됩니다.
// - 2는 조건을 만족하므로 다음 단계로 전달(yield)됩니다.
L.map((a) => a * a), // 3. 지연 평가 매핑: 필터링된 각 요소(짝수)를 제곱하는 매핑 함수를 생성합니다.
// - 2가 전달되면 2 * 2 = 4를 계산하여 다음 단계로 전달합니다.
take(amount), // 4. 지연 평가 제한: 매핑된 결과에서 amount(2)만큼의 요소만 가져옵니다.
// - 이 때 amount 만큼 L.map이 반환한 함수를 호출합니다.
// - L.map이 반환한 함수가 호출되면 L.filter가 반환한 함수가 재호출됩니다.
// - amount 만큼 L.map 이 반환한 함수가 호출되었다면 result 배열엔 [4,16] 이 담겨있고 해당 값을 반환 합니다.
reduce(add) // 5. 최종 결과 계산: 가져온 요소들을 모두 더합니다. (4 + 16 = 20)
);
};
// 주어진 iterable([1, 2, 3, 4, 5, 6, 7])에서 2개의 짝수를 제곱하여 더한 결과를 계산합니다.
func([1, 2, 3, 4, 5, 6, 7], 2); // 결과: 20지연평가를 구현하는 방식은 경우에 따라 다른걸로 아는데, 이는 추후 공부하며 더 알아가도록 하자!
회고
사실 코드에 정답은 없다고 한다지만 취향은 확실히 있는 거 같다. 호호 나는 개인적으로 이런 패러다임이 마음에 드는 거 같다.
최근 해당 영상에 발표자인 유인동님의 깃허브를 보다보면 최근엔 객체지향과 혼합한 멀티 프로그래밍 패러다임에 대한 책과 영상을 준비하고 계신듯 하다.
얼른 익혀본다음 그런 패러다임도 배워봐야지
뭔가 바이블처럼 바라볼 패러다임이 있으니 코드의 좋고 나쁨을 판단 할 객관적인 지표가 생기는 거 같아서 만족스럽다. 다만 너무 한 곳에 편향되어 있는 사람이 되지 않도록 노력해야겠다.